 gautier.dev
gautier.devBuilding a search engine in a day
How is Marginalia, a search engine built by a single person, so good?
How hard can it be to build a search engine? I had no idea until a few days ago, when I decided to build one for this very website. The constraints are quite different from a general search engine:
- No need to crawl the web, I already have all the data.
- The whole search engine should be able to run client-side.
- It should be small and fast.
Here is how small and fast it is to load the whole search engine and associated data:
Loading search engine and index...
In this article I will explain how I built an Algolia-like search engine in a day, with a naive yet effective ranking algorithm. There are two parts to this search engine: the indexing and the searching. The indexing is done at build time, and the searching is done at run time, client-side. The heavy lifting should be done at build time, so that the client-side search is fast.
These two steps work roughly as follows:
#Indexing articles
All my articles are written in markdown, which is made easy to parse by the remark parser. The first step is to parse all the markdown files and normalize their text data into a format that can be easily processed for the next steps.
Let’s take this sample markdown file:
# This is a heading
This is a paragraph... with **important** words.
The first three indexing steps (parsing, tokenization and normalization) transform the markdown into a list of weighted extracts. The structure of this list maps the one of the markdown document. Each root node (heading, paragraph) will map to one extract. Each extract is then a list of strings, with an associated weight. For instance, headings and bold words will have a higher weight than regular words.
[
// Two root nodes
// 1. Heading
[
{
"original": "This is a heading",
"normalized": "this is a heading",
"weight": 2
}
],
// 2. Paragraph
[
// The paragraph contains three text nodes of different weights:
{
"original": "This is a paragraph... with ",
// The normalized extract is lowercase and without punctuation
"normalized": "this is a paragraph with ",
"weight": 1
},
{
"original": "important",
"normalized": "important",
"weight": 2
},
{
"original": " words.",
"normalized": " words ",
"weight": 1
}
]
]
The next step is to sum the weights of the extracts for each word, and store the result in a map. Words of this map are now known as keywords.
{
"this": 3,
"is": 3,
"a": 3,
"heading": 2,
"paragraph": 1,
"with": 1,
"important": 2,
"words": 1
}
The final step is to favor rare keywords and remove too common ones. To do so, I use the following heuristics:
- If a keyword is present in more than half of the articles, it is removed.
- Divide the score of a keyword by the number of articles it can be found in (written as ).
I developed the following formula to make the scoring as useful as possible:
The 5 factor is arbitrary to produce scores mostly between between 0 and 100. The dividend will favor the number of matches 1 and 2 equally, and then decrease the score for higher numbers of matches. This is to favor rare keywords.
The resulting index is a map of maps:
{
// Maps keywords to matching articles
"javascript": {
// Each article is associated with the weight of the keyword
"state-of-js": 8,
"finite-state-automatons": 2
},
"state": {
"finite-state-automatons": 14,
"state-of-js": 5
}
}
With this index, searching for “javascript” will return the article state-of-js first, but “javascript state” will return finite-state-automatons first.
This concludes this first part on how the index is built. The whole indexer can be found on GitHub.
#Searching the index
Searching the index really is the easy part. It’s done in two steps: matching individual keywords against the index to get a list of matching articles, and then keeping only the articles that match all keywords.
Searching “search engine” in the following index:
{
"search": {
"search-engine-in-a-day": 25,
"svelte-tenor-1": 13
},
"engine": {
"finite-state-automatons": 14,
"search-engine-in-a-day": 5
}
}
Will only return search-engine-in-a-day, as it is the only article that matches both keywords.
The whole search algorithm can be found on GitHub.
#Explore the index
The following table allows you to explore the index of this very website, as created by the indexer. It is a list of keywords, with the articles they match and their score. It will be updated as I add more articles to the website.
Loading...
#Additional features
While indexing and searching are the core features of a search engine, there are a few additional features that all users expect from a search engine:
The search input should have auto-completion, helping the user to find relevant keywords.
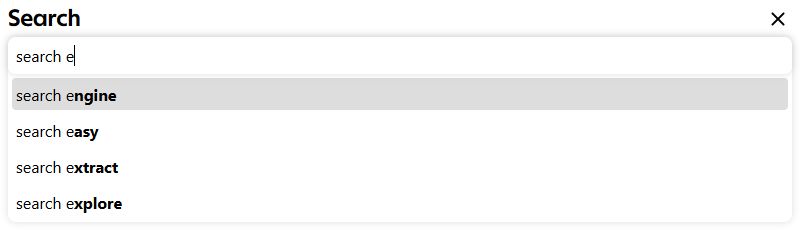
The input field should suggest a coherent search query The search results should contain a relevant extract of the article, with the matching keywords highlighted.
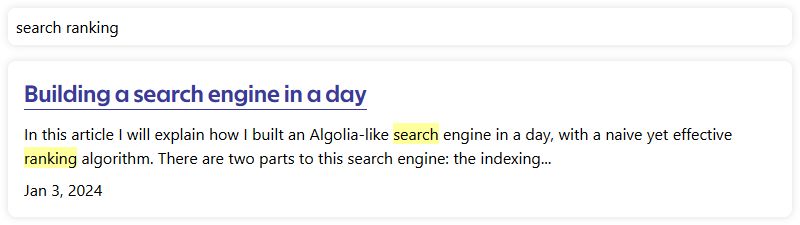
The search result should contain a relevant extract of the article 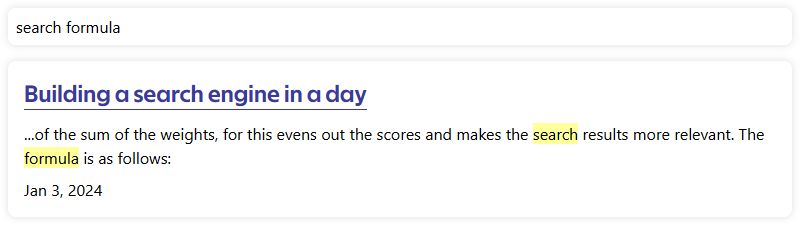
search appears many time in the article, but the closest highlights are picked



I won’t go into the details of these features, as they were built past the one-day mark. If you read the source code, you’ll find that these two features account for most of the complexity of the search engine.